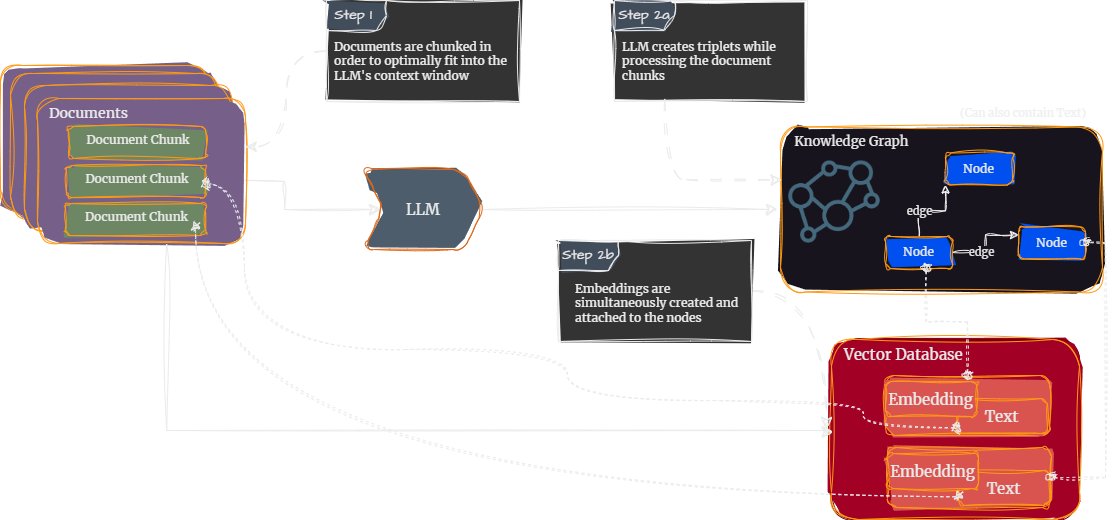
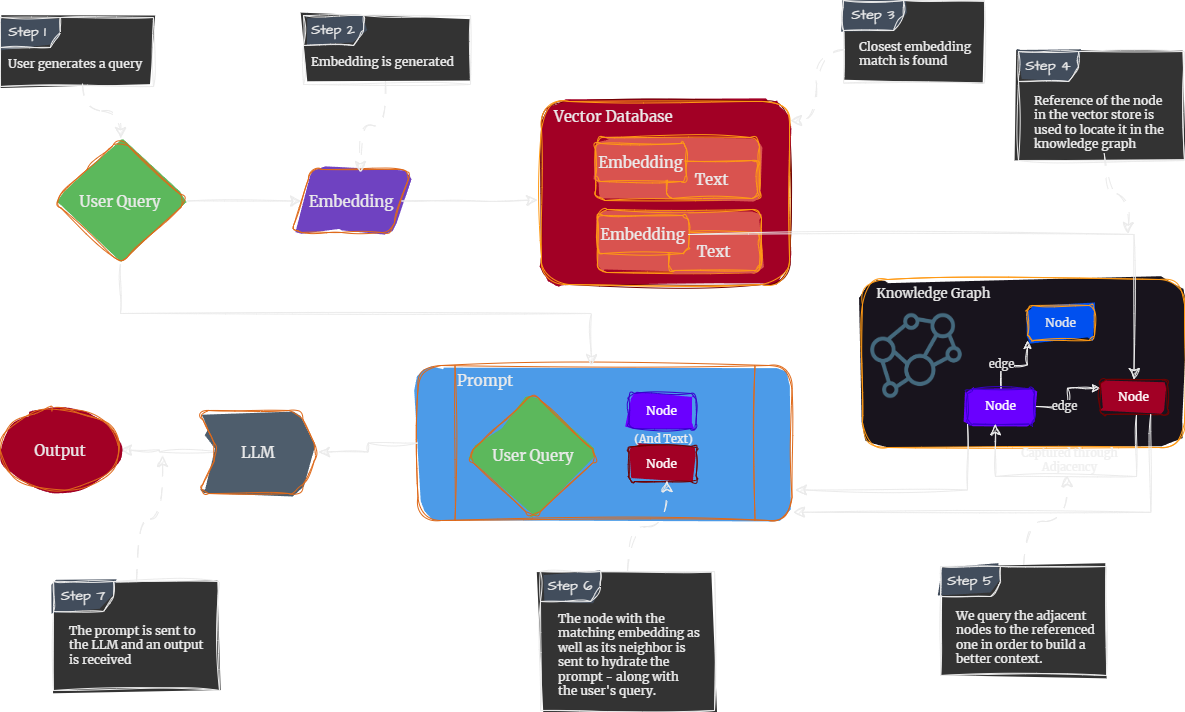
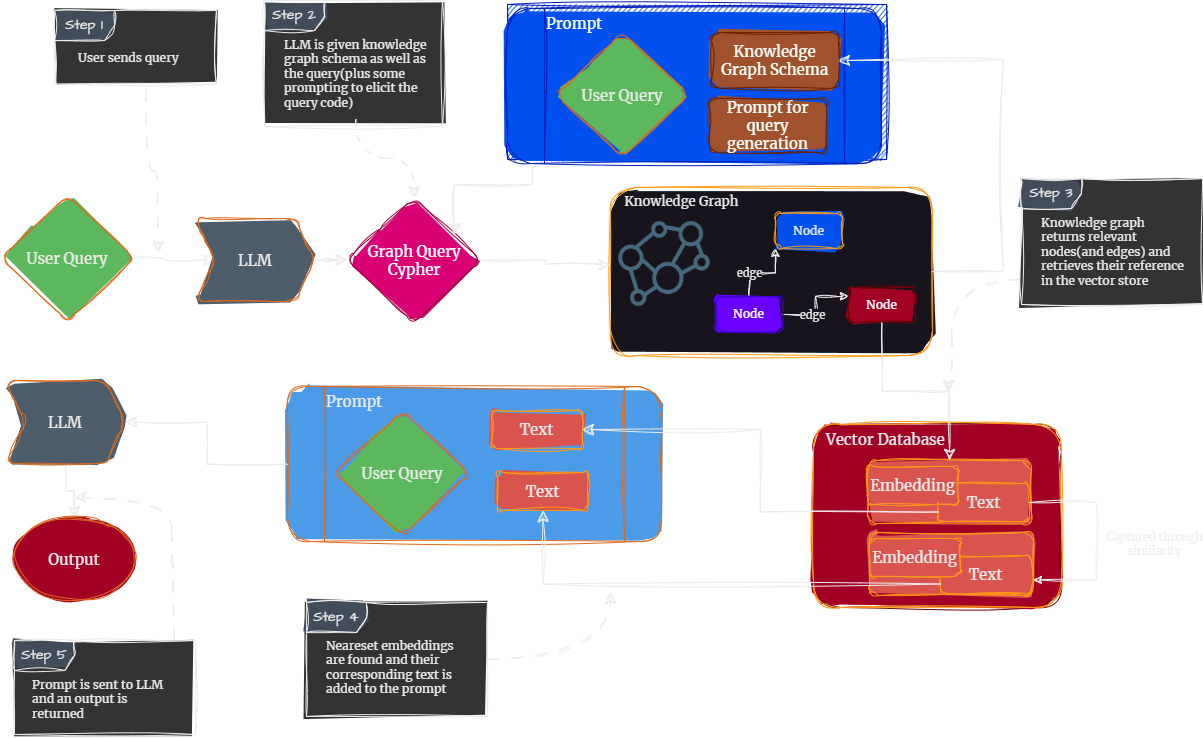
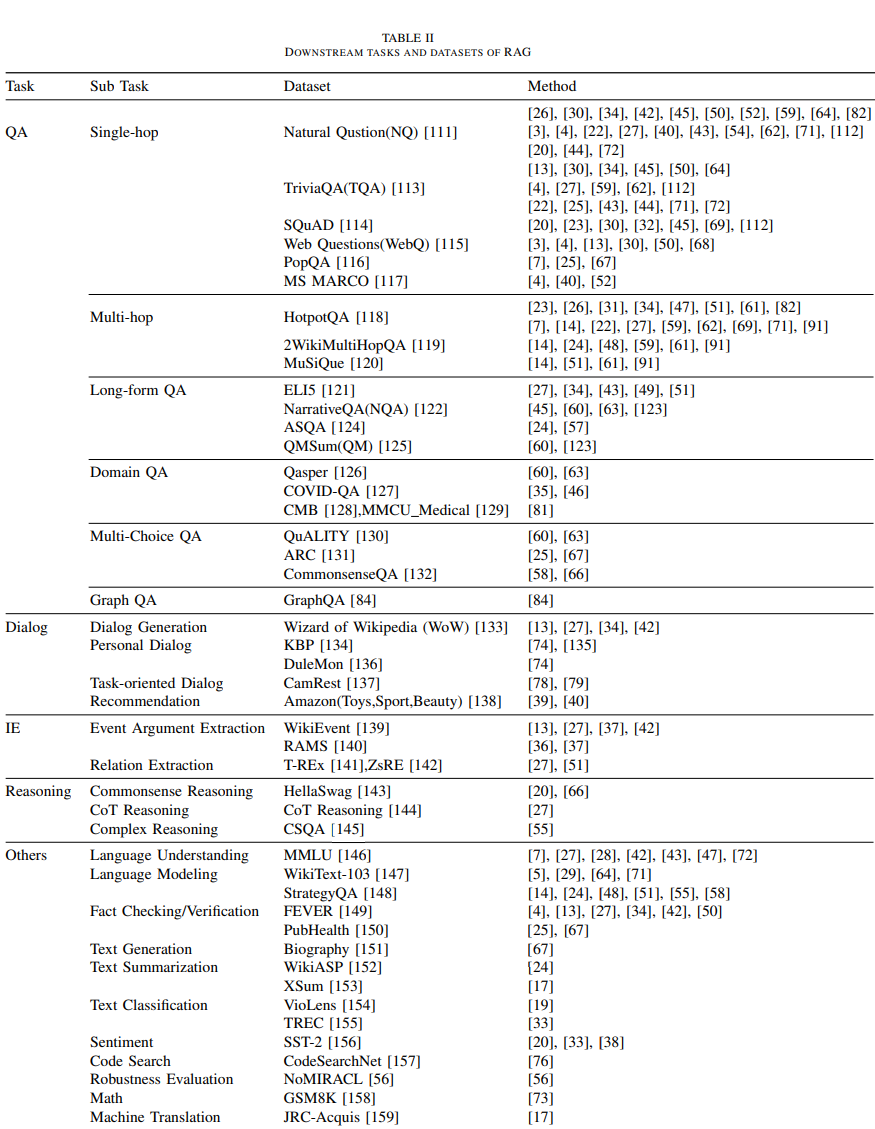
{'id': '2hop__153573_109006',
'paragraphs': [{'idx': 0,
'title': 'History of the Internet',
'paragraph_text': "Precursors to the web browser emerged in the form of hyperlinked applications during the mid and late 1980s (the bare concept of hyperlinking had by then existed for some decades). Following these, Tim Berners - Lee is credited with inventing the World Wide Web in 1989 and developing in 1990 both the first web server, and the first web browser, called WorldWideWeb (no spaces) and later renamed Nexus. Many others were soon developed, with Marc Andreessen's 1993 Mosaic (later Netscape), being particularly easy to use and install, and often credited with sparking the internet boom of the 1990s. Today, the major web browsers are Firefox, Internet Explorer, Google Chrome, Opera and Safari.",
'is_supporting': False},
{'idx': 1,
'title': 'Ceville',
'paragraph_text': "Ceville is a humorous graphic adventure video game developed by the German game studio Realmforge Studios and published by Kalypso Media. Despite the game's use of 3D environments and models, the gameplay is very true to the graphical point-and-click adventure tradition of gameplay, immortalized by game series like Monkey Island from LucasArts and the King's Quest series from Sierra Online.",
'is_supporting': False},
{'idx': 2,
'title': 'Zipline Safari',
'paragraph_text': "Zipline Safari is a zip-line course in Florida. It is the only zip-line course in the state, and is claimed to be the world's only zip-line created for flat land. Zipline Safari opened on 16 January 2009 in Forever Florida, a wildlife attraction near Holopaw, Florida. The zip-line cost $350,000 to build, and consists of nine platforms built up from the ground and traveled between by zip-lining. Forever Florida built the course to promote ecotourism and interaction with the natural environment of Florida.",
'is_supporting': False},
{'idx': 3,
'title': 'Parc Safari',
'paragraph_text': "Parc Safari is a zoo in Hemmingford, Quebec, Canada, and is one of the region's major tourist attractions; that has both African & Asian species of elephant.",
'is_supporting': False},
{'idx': 4,
'title': 'The Reporter (TV series)',
'paragraph_text': 'The Reporter is an American drama series that aired on CBS from September 25 to December 18, 1964. The series was created by Jerome Weidman and developed by executive producers Keefe Brasselle and John Simon.',
'is_supporting': False},
{'idx': 5,
'title': 'Earthworm Jim 4',
'paragraph_text': 'Earthworm Jim 4 is a video game in the "Earthworm Jim" series. It was originally announced by Interplay Entertainment in 2008, and referred to by Interplay as "still in development" in May 2011. Later commentary from individual developers would claim that development hadn\'t started, though desire to create a new entry in the series remained. In May 2019, it was announced that the game was to begin development exclusively for the upcoming Intellivision Amico console.',
'is_supporting': False},
{'idx': 6,
'title': 'Adobe Flash Player',
'paragraph_text': 'Availability on desktop operating systems Platform Latest version Browser support Windows XP and later Windows Server 2003 and later 27.0. 0.183 Firefox, Chrome, Chromium, Safari, Opera, Internet Explorer, Microsoft Edge Windows 2000 11.1. 102.55? Windows 98 and ME 9.0. 115.0? Windows 95 and NT 4 7.0. 14.0? Mac OS X 10.6 or later 27.0. 0.183 Firefox, Chrome, Chromium, Safari, Opera Mac OS X 10.5 10.3. 183.90? Classic Mac OS, PowerPC 7.0. 14.0? Classic Mac OS, 68k 5.0? Linux 27.0. 0.183 Firefox, Chrome, Chromium, Opera',
'is_supporting': False},
{'idx': 7,
'title': 'Apple Inc.',
'paragraph_text': "Apple Inc. is an American multinational technology company headquartered in Cupertino, California that designs, develops, and sells consumer electronics, computer software, and online services. The company's hardware products include the iPhone smartphone, the iPad tablet computer, the Mac personal computer, the iPod portable media player, the Apple Watch smartwatch, the Apple TV digital media player, and the HomePod smart speaker. Apple's consumer software includes the macOS and iOS operating systems, the iTunes media player, the Safari web browser, and the iLife and iWork creativity and productivity suites. Its online services include the iTunes Store, the iOS App Store and Mac App Store, Apple Music, and iCloud.",
'is_supporting': False},
{'idx': 8,
'title': 'Philadelphia Zoo',
'paragraph_text': 'The Philadelphia Zoo, located in the Centennial District of Philadelphia, Pennsylvania, on the west bank of the Schuylkill River, was the first true zoo in the United States. Chartered by the Commonwealth of Pennsylvania on March 21, 1859, its opening was delayed by the American Civil War until July 1, 1874. It opened with 1,000 animals and an admission price of 25 cents. For a brief time, the zoo also housed animals brought over from safari on behalf of the Smithsonian Institution, which had not yet built the National Zoo.',
'is_supporting': False},
{'idx': 9,
'title': 'Web browser',
'paragraph_text': "Apple's Safari had its first beta release in January 2003; as of April 2011, it had a dominant share of Apple-based web browsing, accounting for just over 7% of the entire browser market.",
'is_supporting': False},
{'idx': 10,
'title': 'List of The 100 episodes',
'paragraph_text': 'The 100 (pronounced The Hundred) is an American post-apocalyptic science fiction drama television series developed by Jason Rothenberg, which premiered on March 19, 2014, on The CW. It is loosely based on a 2013 book of the same name, the first in a book series by Kass Morgan. The series follows a group of teens as they become the first people from a space habitat to return to Earth after a devastating nuclear apocalypse.',
'is_supporting': False},
{'idx': 11,
'title': 'Shiira',
'paragraph_text': 'Shiira (シイラ, Japanese for the common dolphin-fish) is a discontinued open source web browser for the Mac OS X operating system. According to its lead developer Makoto Kinoshita, the goal of Shiira was "to create a browser that is better and more useful than Safari". Shiira used WebKit for rendering and scripting. The project reached version 2.3 before it was discontinued, and by December 2011 the developer\'s website had been removed.',
'is_supporting': False},
{'idx': 12,
'title': 'Traffic Department 2192',
'paragraph_text': 'Traffic Department 2192 is a top down shooter game for IBM PC, developed by P-Squared Productions and released in 1994 by Safari Software and distributed by Epic MegaGames. The full game contains three episodes (Alpha, Beta, Gamma), each with twenty missions, in which the player pilots a "hoverskid" about a war-torn city to complete certain mission objectives. The game was released as freeware under the Creative Commons License CC BY-ND 3.0 in 2007.',
'is_supporting': False},
{'idx': 13,
'title': 'Maciej Stachowiak',
'paragraph_text': "Maciej Stachowiak (; born June 6, 1976) is a Polish American software developer currently employed by Apple Inc., where he is a leader of the development team responsible for the Safari web browser and WebKit Framework. A longtime proponent of open source software, Stachowiak was involved with the SCWM, GNOME and Nautilus projects for Linux before joining Apple. He is actively involved the development of web standards, and is a co-chair of the World Wide Web Consortium's HTML 5 working group and a member of the Web Hypertext Application Technology Working Group steering committee.",
'is_supporting': False},
{'idx': 14,
'title': 'Ellery Queen (TV series)',
'paragraph_text': 'Ellery Queen is an American TV series, developed by Richard Levinson and William Link, who based it on the fictional character of the same name. The series ran on NBC from September 11, 1975, to April 4, 1976 featuring the titular fictional sleuth. The series stars Jim Hutton as the titular character, and David Wayne as his father, Inspector Richard Queen.',
'is_supporting': False},
{'idx': 15,
'title': 'Hunting',
'paragraph_text': 'In the 19th century, southern and central European sport hunters often pursued game only for a trophy, usually the head or pelt of an animal, which was then displayed as a sign of prowess. The rest of the animal was typically discarded. Some cultures, however, disapprove of such waste. In Nordic countries, hunting for trophies was—and still is—frowned upon. Hunting in North America in the 19th century was done primarily as a way to supplement food supplies, although it is now undertaken mainly for sport.[citation needed] The safari method of hunting was a development of sport hunting that saw elaborate travel in Africa, India and other places in pursuit of trophies. In modern times, trophy hunting persists and is a significant industry in some areas.[citation needed]',
'is_supporting': False},
{'idx': 16,
'title': 'Safari School',
'paragraph_text': 'Safari School is a BBC Two reality television series presented by Dr Charlotte Uhlenbroek in which eight celebrities take part in a four-week ranger training course in the Shamwari Game Reserve in South Africa.',
'is_supporting': False},
{'idx': 17,
'title': 'African Safari Wildlife Park',
'paragraph_text': 'The African Safari Wildlife Park is a drive through wildlife park in Port Clinton, Ohio, United States. Visitors can drive through the preserve and watch and feed the animals from their car. Visitors can spend as much time in the preserve as they wish, observing and feeding the animals, before proceeding to the walk through part of the park, called Safari Junction. The park is closed during the winter.',
'is_supporting': False},
{'idx': 18,
'title': 'White armored car',
'paragraph_text': 'The White armored car was a series of armored cars developed by the White Motor Company in Cleveland, Ohio from 1915.',
'is_supporting': False},
{'idx': 19,
'title': 'Blue Tea Games',
'paragraph_text': 'The 14th game of this series. The BETA game was released in September 2017. This episode will be developed by Blue Tea Games who return to the series since 2014.',
'is_supporting': False}],
'question': "Who developed the eponymous character from the series that contains Mickey's Safari in Letterland?",
'question_decomposition': [{'id': 153573,
'question': "What series is Mickey's Safari in Letterland from?",
'answer': 'Mickey Mouse',
'paragraph_support_idx': None},
{'id': 109006,
'question': 'Who developed #1 ?',
'answer': 'Walt Disney',
'paragraph_support_idx': None}],
'answer': 'Walt Disney',
'answer_aliases': [],
'answerable': False}