Despite much anticipation and even more fear, it pains me to say that LLMs will not be summoning the Machine God anytime soon.
Origins
Language is a human creation. Whether it’s English, Latin, Aramaic, or even C++, language is created by humans – either artificially through intentionality, as in case of the programming language you know and love, or through the waterfall of time and our basic need to communicate with one another, we created the words, structures, and abstractions we utter daily. In any case, they are very sapiens constructs, necessarily bound to our capacity to understand and manipulate the world around us.
We are agentic beings tugged by evolution to survive and multiply. An agent that is reacting to its environment and acting upon it must have a model of the reality it inhabits. It doesn’t have to be a great model, hell, it doesn’t even have to be a good model. It has to be a satisfactory model that weighs an extraordinary number of trade offs. There is no free lunch, especially in an antagonistic universe that is doing everything in its power to feed its entropic addiction and tear you apart, atom by atom. We cannot afford to model the entire universe in our expensive brains, which at only 2% of our body mass consume 20% of our energy. Let’s take a step back for a second, or roughly half a billion years – brains made it to the scene via centralization and cephalization. Organisms initially had distributed nervous systems called nerve nets, which we see in hydras and jellyfish today. Neurons were simplistic logical gates where an activation would lead to a clear reaction of the organism - reflexive. As chance had it, as the nervous system migrated to the center of the organism over hundreds of millions of years, it became more effective at helping them respond to stimuli and thereby increased their fitness. Eventually, a very large cluster of neurons not only centralized but cephalized, it gathered at the anterior end of the body(think flatworms).

Neurons in proximity have a world of opportunity to connect to one another in myriads of ways at an extremely low cost. Look, ma, a biological processor. Evolution accelerated in ways that many people don’t appreciate thanks to this one little trick – the sensation to action pipeline became the perfect experimentation bedrock now that the neurons could assemble in a nearly infinite amount of ways. The integration of signals from the sensory systems of the organism allowed it to model the world around it in a manner that was previously impossible. Much like our nematode friends, we integrate information from numerous modalities and model the world around us for the purpose of acting on it.
Language
Nematodes don’t really have a way of expressing their internal model of the world, but we do. Even if they could, it’d be pretty damn boring. “Bright light, bad smell, pressure on tail, move right, profit” Although I’m fairly certain you’d rather be interacting with it than a few people you can think of. Language allows us to express our model of the world to other people for the purposes of cooperation, conflict avoidance, and informational exchange. Through the experimentation with phonation(making sounds) and the growth of our brains necessary to optimize our behavior in an uncertain environment, selective pressures precipitated the development of language. If Grog says “urrghhhhu” and Brog says “grruuuugh”, and they both now have a higher likelihood of finding a juicy antelope meal, the incentive to experiment with language grows in their own lifetimes. If Grog and Brog now have more children because of their linguistic prowess, this also contributes to an evolutionary process which supports linguistic development. Their progeny do not start off with a blank slate of knowledge; they learn from their parents, and improve upon it. This is known as Natural Language. The kids of Grog and Brog can now take the phonemes they learned from their parents and improve upon them for more complex needs – maybe they learn to represent the weather, or perhaps they learn how to represent the difference between hunting and foraging. In any case, this naturally creates a complex structure out of necessity.
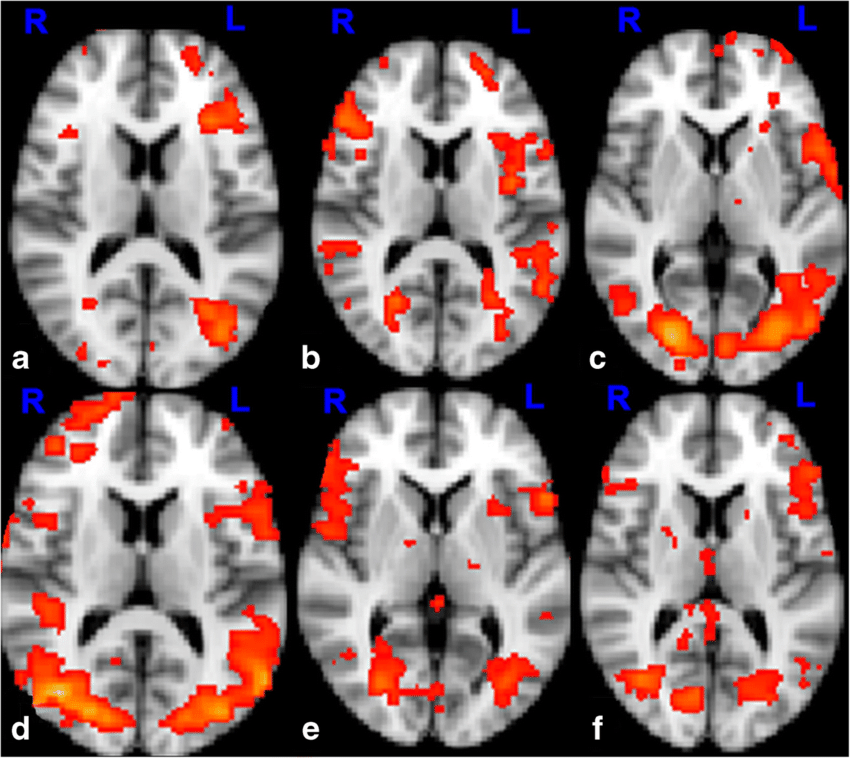
If you look at fMRIs taken of people performing language-related tasks, the screen tends to light up like a Christmas tree. The brain is a very specialized organ with hyperspecialized regions within it, yet the task of language interpretation and generation is highly distributed, and quite calorie-consuming. Language is able to access the complex model we’ve created of our world. It is language that has allowed us to launch spaceships and to pontificate on the existence of dark matter. We are still the descendants of Grog and Brog, who used a form of language to thrive, and our brains aren’t morphologically different; we also still have the same incentives give or take an unremarkable error margin. Keep this in mind.
The progression of our linguistic prowess involves offloading it from our memory and onto some physical medium. In turn, this influenced its future development.

LLMs
Large Language Models(LLMs) have shocked the very core of humanity. Diffusion models which are responsible for image and video generation have had a similar effect. As it turns out, when we create a clever neural architecture in silico(on computer), throw all of the data we have generated as a human species at it, and the compute/energy equivalent of running a nuclear reactor(1GWh) for 50 hours with the sole purpose of training the model, we create something so novel and uncanny that we begin singing songs of apocalypse and salvation.

For comparison, a human brain only requires ~0.0088 Gigwatt hours to run for a lifetime.
LLMs are trained with a highly curated set of nearly all(contentiously) of the data digitally available: approximately 10 trillion words. Like humans, they develop a model of the world, but through a process that helps them predict the next token. A token is typically a group of letters that cooccur - e.g. moth + er, but it can also be something functional like <|endoftext|> which signifies the end of a response. In addition, they are also trained to answer questions in a manner that is favorable to the corporation building the model and to avoid outputting what they believe are naughty words and ideas – this concept is often viewed as alignment.
At its core, a model is a compressed and accessible form of the data it is trained on, otherwise, it wouldn’t be a very useful model. An input passes through the model to produce an output. We model the vast amounts of inputs we receive from our sensory organs and observations of cause and effect; this model is stored in our big beautiful brains. This creates a compressed latent space of information aligned in way that we can access to act upon the world we inhabit. Another compressive and decompressive process involves our decoding of this information and encoding it into words for the purposes of communicating.

An LLM is trained on this information that we’ve produced communicating with one another in casual and technical conversations in forums, through books, blogs, and so forth. While this is extremely lossy information of a human’s model of the world and thereby an even more lossy model of reality, it is composed of immensely wide and diverse sets of words used to express ideas throughout written history.
Not surprisingly, it is a transcendental experience to speak to an LLM that contains an acceptable model of our world tuned to respond conversationally. It is a superb summarizer of text, and it holds a magnificent amount of information that it can access given the right prompt. It is a majestic wordsmith, as it operates across syntax and semantics incredibly well. Ask it to write you a song about a specific topic, and it’ll create something unique.

What it lacks is pragmatics. Pragmatics involves attaching the relevance of situational context to human speech. An LLM does not act upon its theory of mind, which it does have access to – just ask it what a person may be motivated by when their dog just ate a box of chocolate, all while they’re struggling to pay rent. The information it has consumed over the huge corpus of data does contain descriptions of how we feel, how we act in relation to those feelings, and what situations create those motivations within us. I have not seen a single successful evaluation of it using this knowledge in any meaningful manner. LLMs excel at written exams, they even excel at programming, but they appear to have no capacity for metacognition. This is ultimately a key reason behind LLMs being referred to as stochastic parrots.
Stochastic parrots are incredible algorithms. They allow us to navigate and extract information in many forms from the entirety of written human knowledge. They do hallucinate, but that is but a technical challenge which is solved by grounding them in a system that can enforce factual consistency. A stochastic parrot serves you, as you imbue it with the pragmatics and purpose it needs. We are the ones who seed them with our own agency. We then refer to them as agents, which may arguably be a misnomer since the agency does not originate from these algorithms. A swarm of these agents directed to any given task is inevitably a multiplier of our productivity.
Stagnation?
Human achievement looks and feels asymptotic when you observe the amount of discoveries and innovations throughout the centuries. Even our capability to extend our own lifespan seems to be leveling out and in many cases, decreasing. I’m an optimist and I yearn for a gold rush of exponentiality, however I am also a realist. We have to acknowledge reality if we want to find a single nugget. I am not particularly fond of pessimists, nor do I respect them, as self-fulling prophecy sticks to them like shit to a pig.

LLMs are inextricably tied to our own intelligence and our model of reality even if they know more facts than any single human alive. Language is already a product of our collective intelligence, and in many cases acts as a positive feedback loop where we use it enhance our own capacity through a series of stacking abstractions. These are the very abstractions that led us to build and exploit the elegance of LLMs in creative ways. However, the acquisition and use of language has always been heavily constrained and driven by the key aspects that pragmatics is concerned with – the need to solve problems, the need to communicate effectively towards a goal, the need to navigate the complexity of the world.
Hype
Despite the incredible capabilities of LLMs, the hype surrounding artificial intelligence has led to a premature leap from the reality of these models. In a comedic sequence of events, the marketers of LLMs and the doomsayers have jumped over Artificial General Intelligence(AGI) straight to Artificial Superintelligence(ASI). ASI used to stand for Artificial Specialized Intelligence, but collective amnesia is one heck of a drug.
Companies like OpenAI and Anthropic throw a bit of preferential ‘function calling’ on their LLMs and like to underscore their agentic ability. In essence, they increase the likelihood of a model responding with a name of a function. It’s equivalent to you have access to func1: given x does y and func2: given y does b, now answer this question, choose one of these functions if necessary to get more information: ... Would you look at that, their valuation just went up by a few billion dollars. The near future likely belongs to Artificial Specialized Intelligence. I’m not necessarily referring to something like AlphaGo, which is able to beat the best human players at Go, although the same concept applies. We can and do create specialized tools with LLMs – humans have to imbue the system with intentionality, agency, and everything that the model inherently lacks due to its nature as a next-word-predictor.
As more compute and data are thrown at the models, they become more proficient when it comes scoring highly on evaluations. The evaluations themselves are created by humans to perform human-centric tasks such as passing various board exams and being able to program software. We shouldn’t expect out-of-distribution performance from the available model, but we can massage the latent space with our input in a way that leads to 99th percentile in-distribution performance.
Anti-Hype
To recap the salient points:
Humans, like all other organisms ingest and compress information about the world into a model for the sake of survival. This is an energetically expensive process and is focused on the elements that help the organism survive and reproduce.
Language is another compressive and expensive process that we use to increase our biological fitness. We compress the model of the world we created for the purposes of communicating certain intents and ideas with others.
LLMs are trained to predict the next token over trillions of tokens(and words). Through this, they gain their own compressed model of the world based on the aforementioned compressed models.
Language is only a subset of human intelligence and excludes the pragmatics of human communication.
(With LLMs) There will not be a singularity. There will be no Skynet. There will only be hype. Can a swarm of AI agents take your job? Probably. Give them a robot to control and they’ll take many, however, they’ll create even more. These AI ‘agents’ are not agentic in their own right - their agency is wound by humans. On their own, they are little more than Game of Life automata.
